在不同的应用或者不同类型的文件下,同一字符表达形式有所不同,如空字节(十六进制为00,文本表达为小正方向,010中默认显示为.,厨师解密显示为nul),如果此时任然复制原来的文本所显示的内容可能会与原来不同,如:
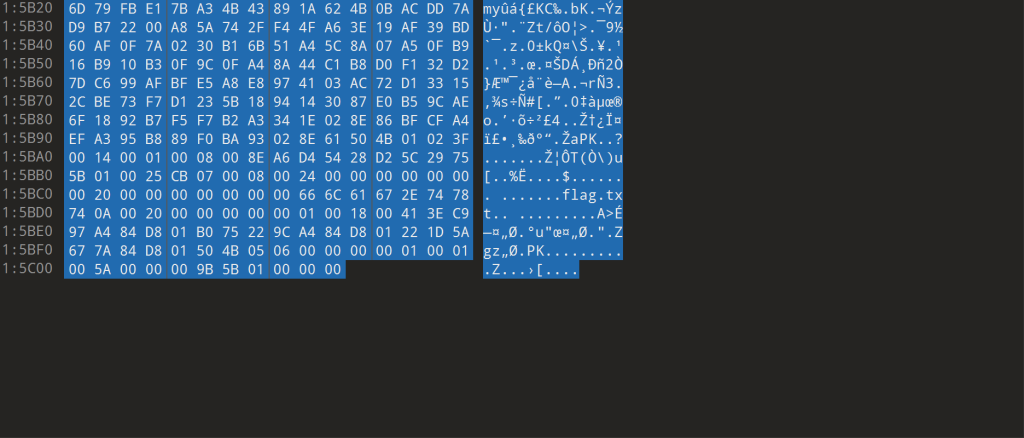
此时我全部复制右边内容ctrl+c,粘贴的内容只有如下
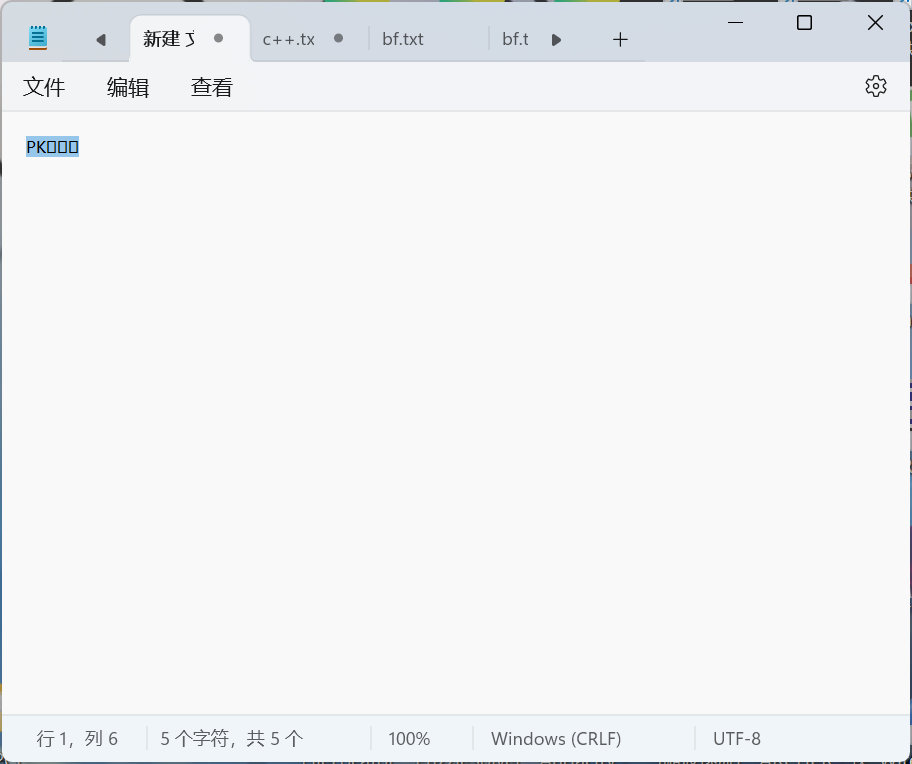
若只复制实际文本内容
粘贴文本可完全显示,可见0字节对粘贴后内容有一定影响
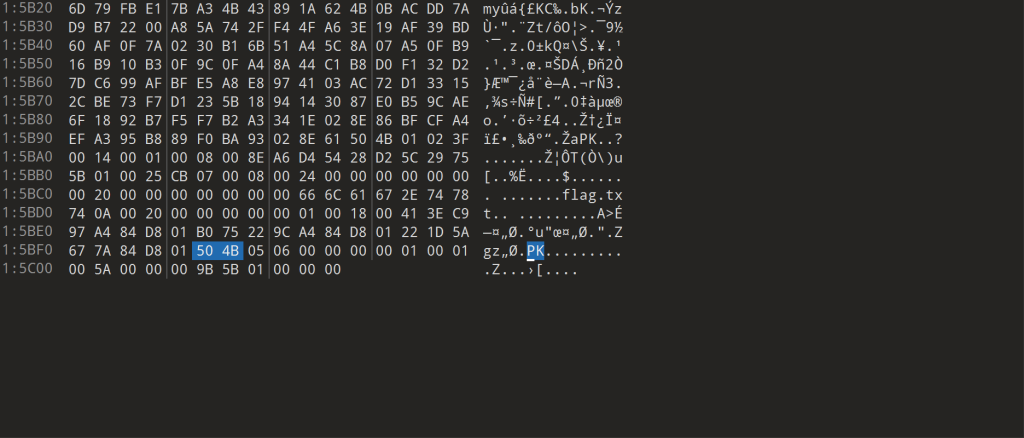
但是0字节对文件结构显示任有作用,如此图包含了0字节能正常打开
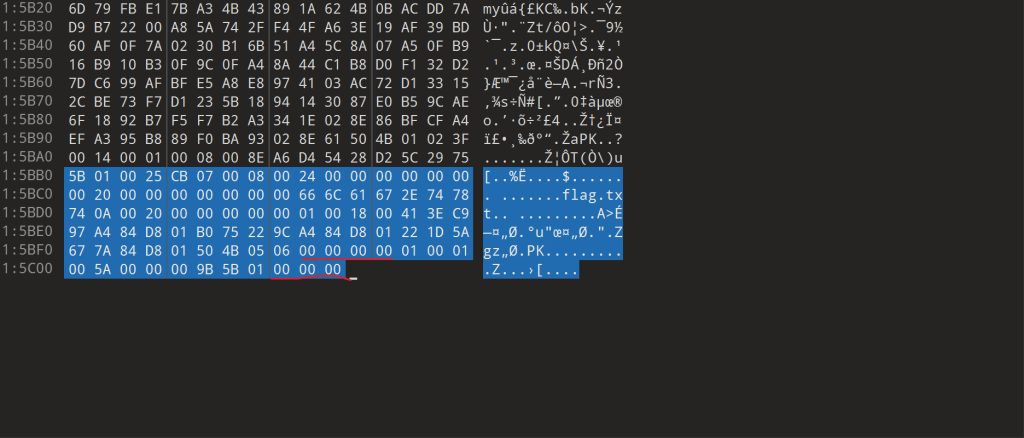
而删除部分0字节后不能正常打开
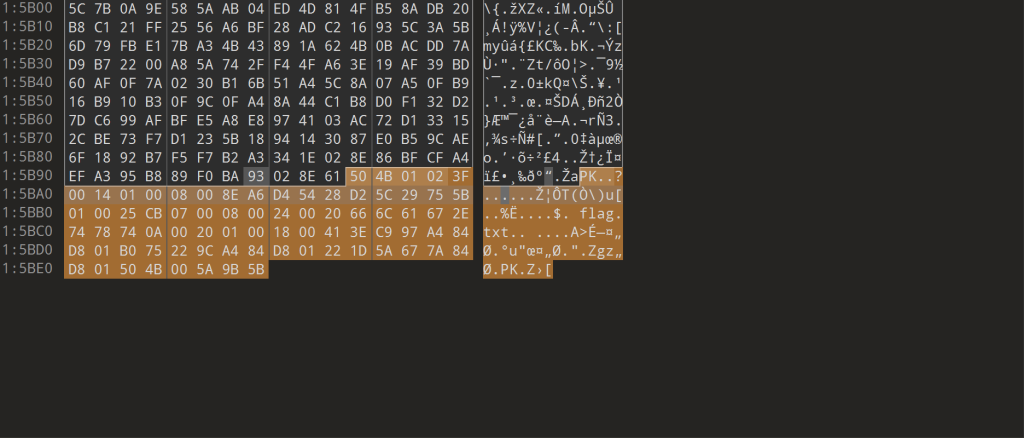
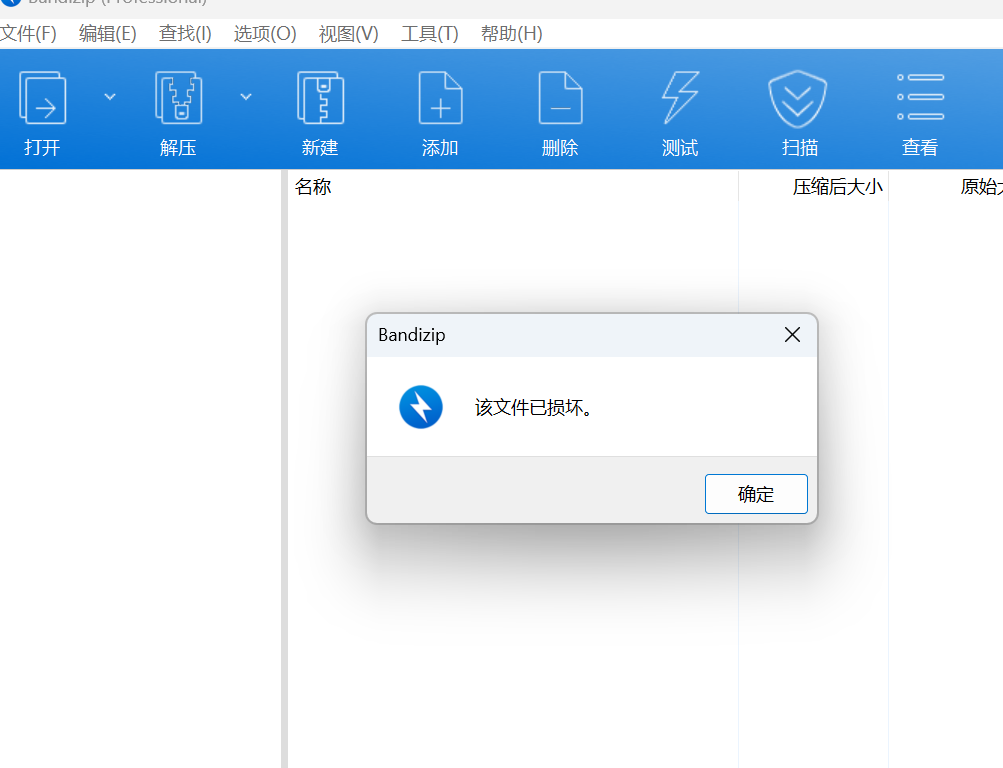
所以对于含0字节等转储有问题的文本内容可以考虑分析其它进制转换再转对应文件->
如base64转16进制,编辑为对应文件
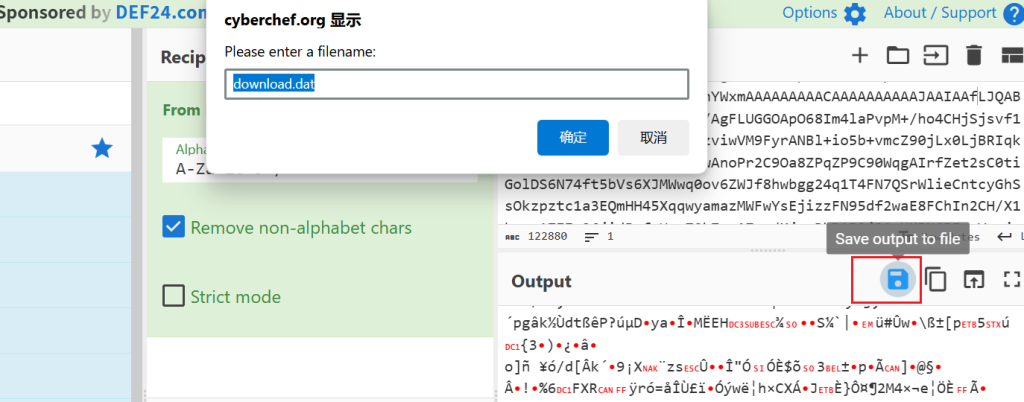
这个问题的核心就是针对一些编码转换后没有中间载体情况,像如果可以直接保存文件的情况下可以直接保存文件就行(例如:CyberChef等可以直接保存文件),因为以上操作的目的都是为了在进行数据转储时避免数据丢失
例题:[鹏城杯 2022]简单取证
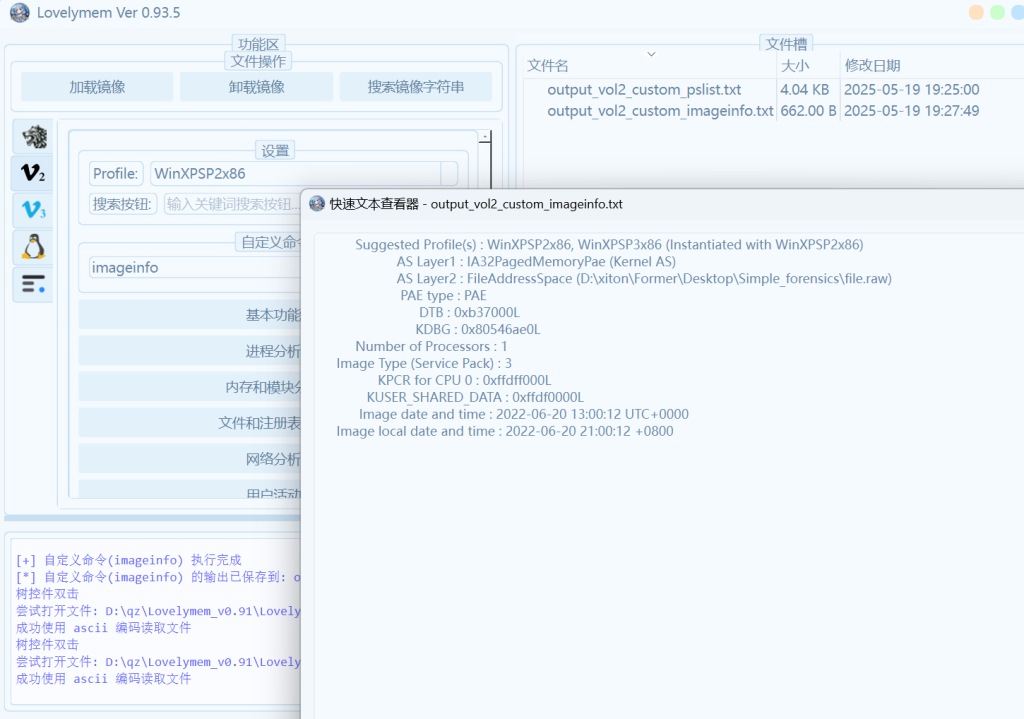
查看进程与信息
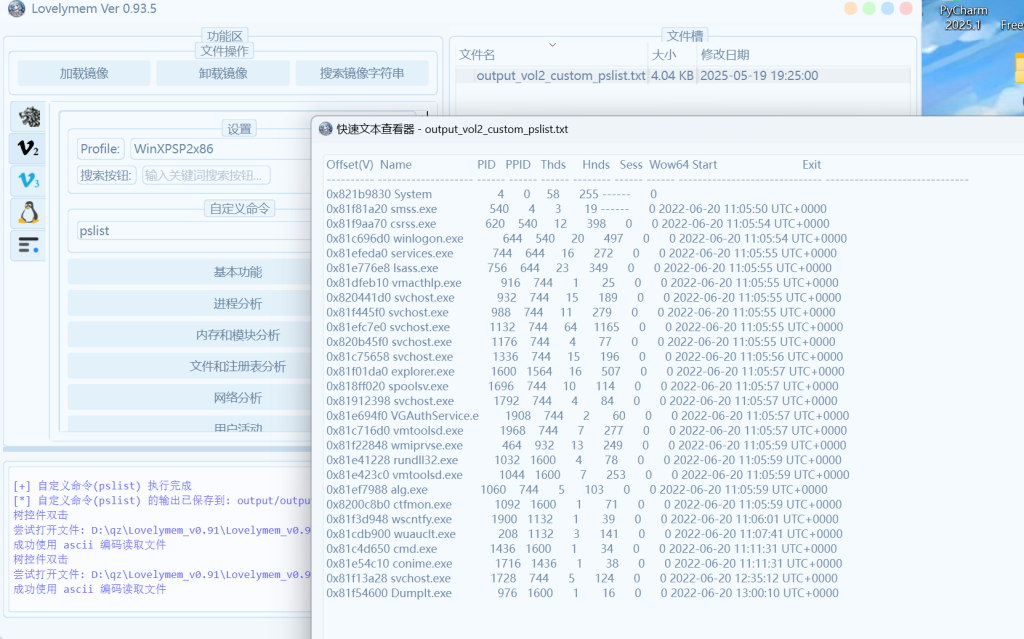
文件扫描,搜索后zip/rar/txt/flag/secret/wav等关键字,
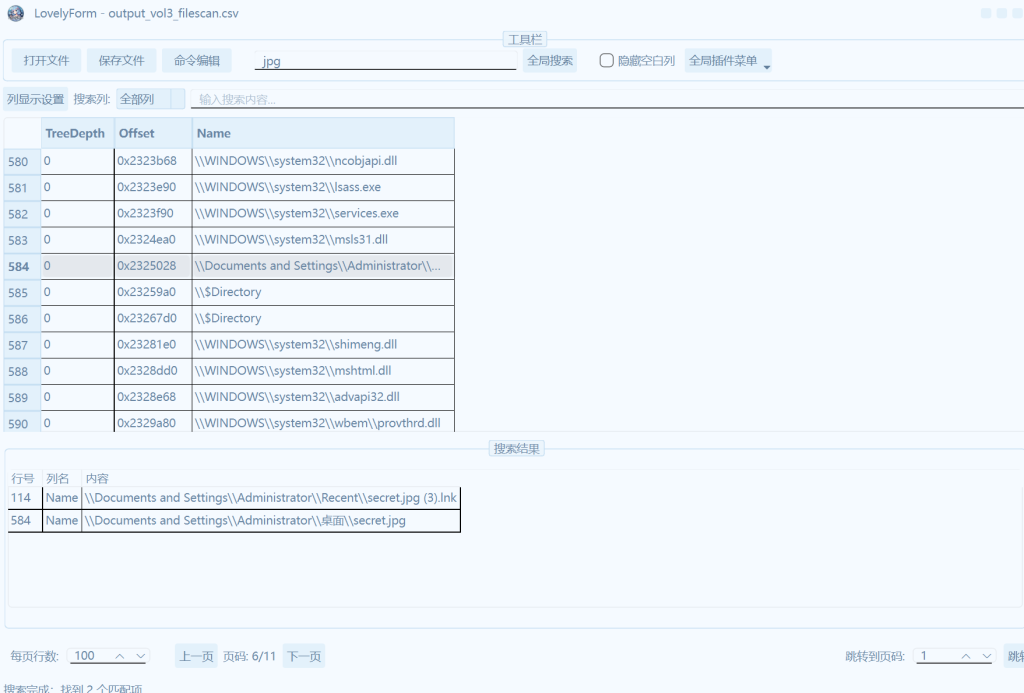
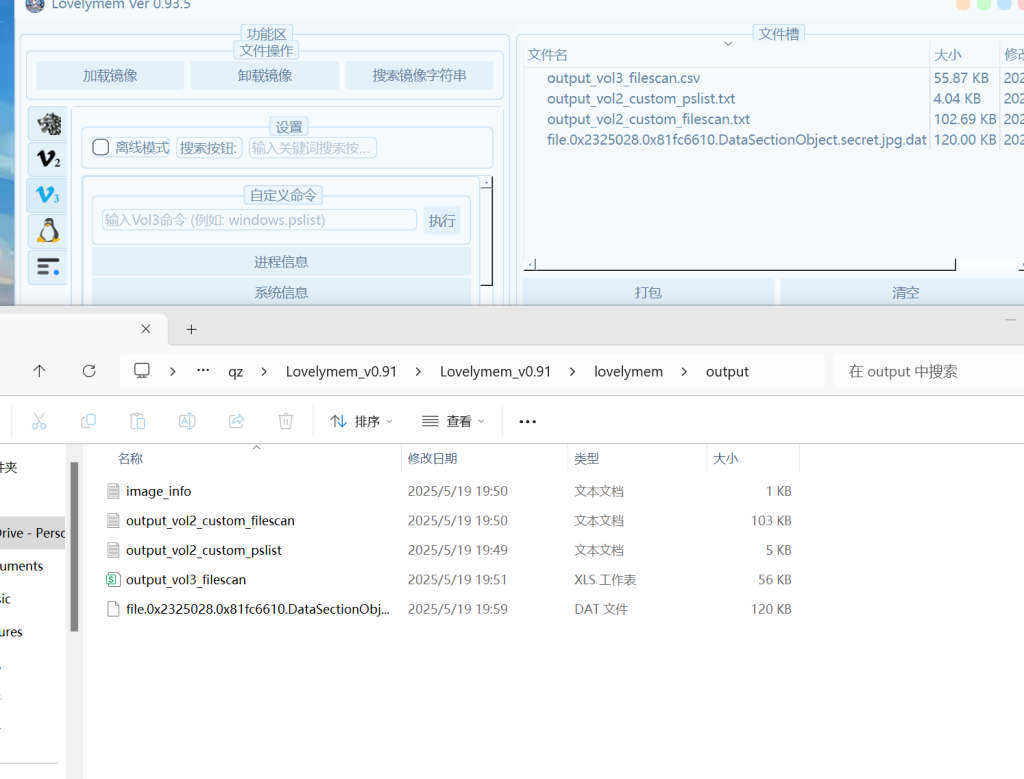
文件导出此工具一般存为dat文件,改后缀即可(注意有一个为.lnk文件为桌面快捷方式)
打开发现是base64编码
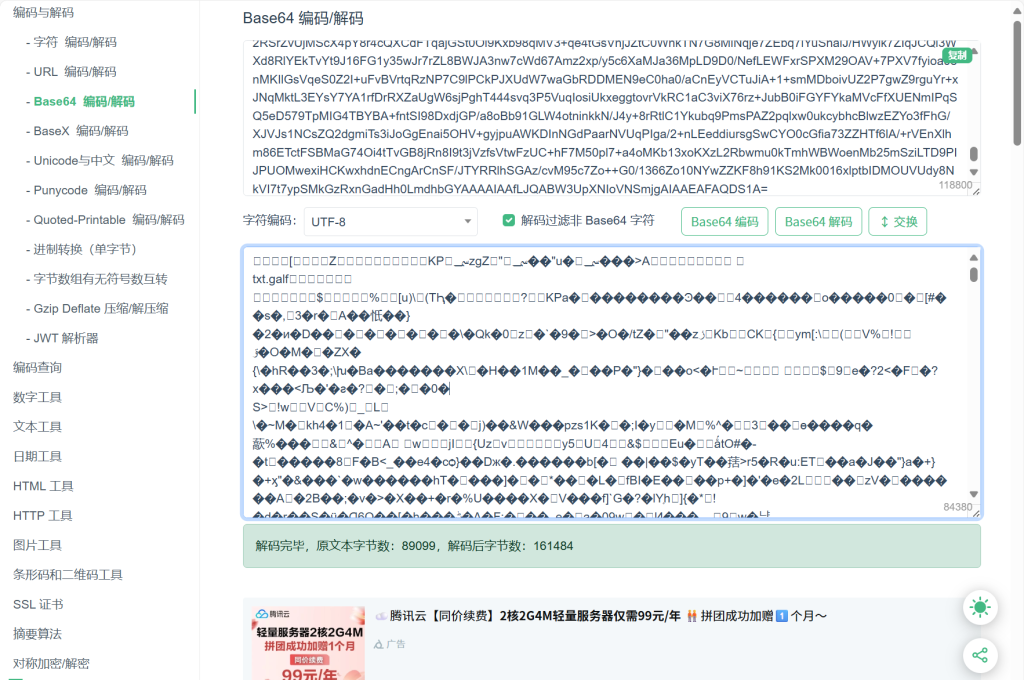
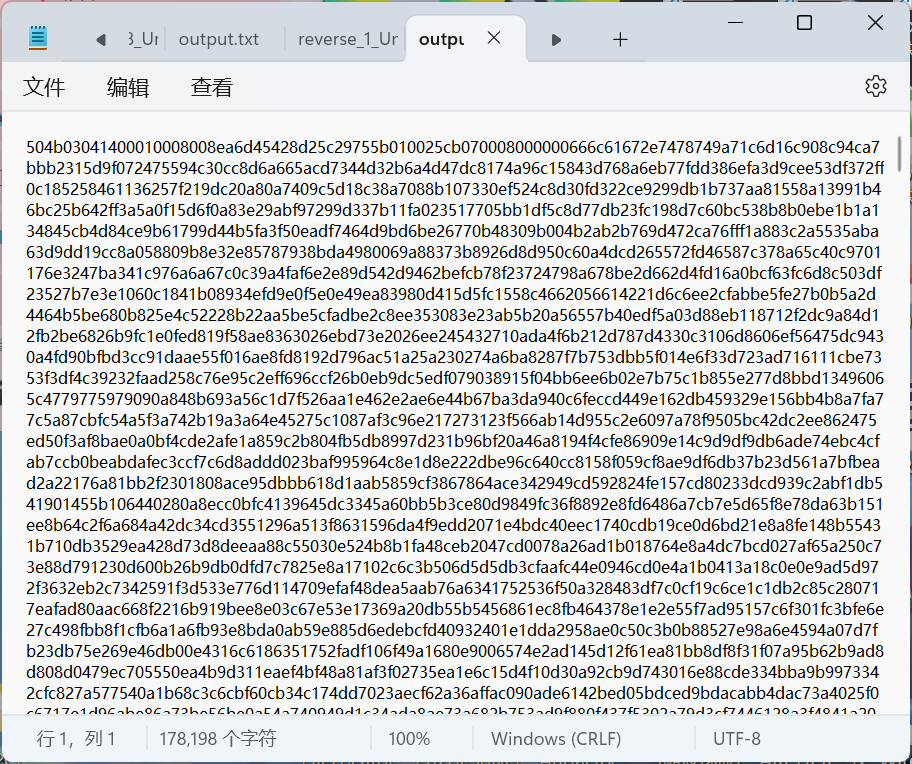
解码发现文本内容,且发现PK,判断为zip压缩包(倒序)进制转换再转对应文件->
原来base64编码直接转16进制,16进制字节倒转(两两一组),再在PuzzleSolver 小绵羊上进行一次整体文本倒转,编辑为对应文件即可(因为这里base64解码后发生了倒转,所有这里有两次倒转)
存为zip

打开发现有密码,cmdscan发现password

注:其实这里直接在厨师上保存文件处理就行,只是这里针对所描述的问题所以绕弯进行了进制转换处理,反而显得有点入机,保存文件具体步骤
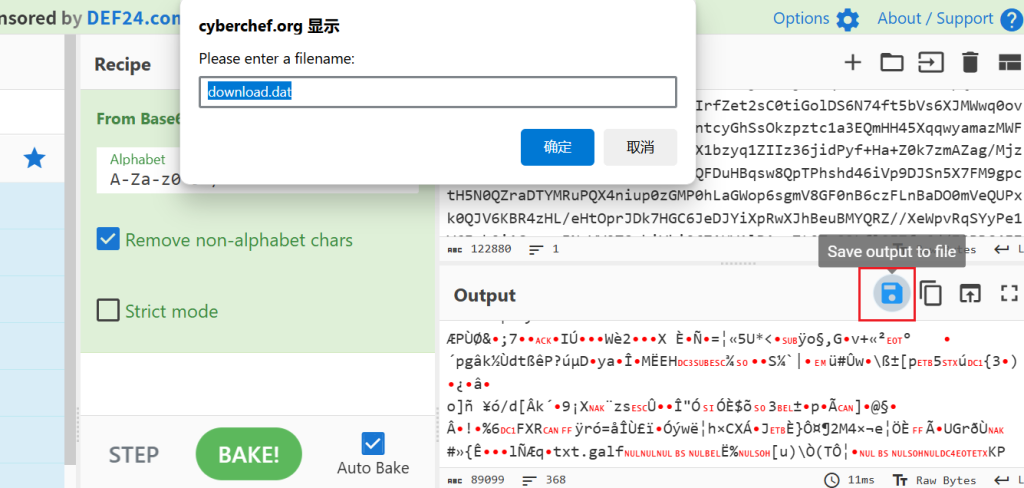
保存后改为txt格式,接下可以直接进行小绵羊倒转
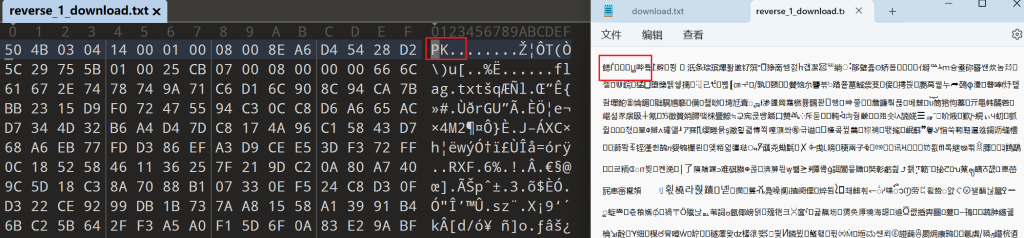
可见虽然记事本内容显示有所差异,但最后010打开发现文件已经处理成功了,这说明转储过程中没有数据损失,达到了预期效果,接下来存为zip即可
最后附上脚本:
base64转16进制:
import base64
import re
def process_files(input_file, output_file):
"""处理文件的Base64到十六进制转换"""
try:
# 读取Base64数据
with open(input_file, 'r') as f:
b64_data = f.read().strip()
# 清洗非法字符
clean_data = re.sub(r'[^a-zA-Z0-9+/=]', '', b64_data)
# Base64解码
binary_data = base64.b64decode(clean_data)
# 转换为十六进制并保存
with open(output_file, 'w') as f:
f.write(binary_data.hex())
print(f"转换成功!输出文件:{output_file}")
return True
except FileNotFoundError:
print(f"错误:输入文件 {input_file} 未找到")
return False
except Exception as e:
print(f"处理失败:{str(e)}")
return False
if __name__ == "__main__":
# ========== 文件路径定义区 ==========
input_filename = r"1.txt" # 输入文件路径
output_filename = 'output1.txt' # 输出文件路径
# 执行转换操作
process_files(input_filename, output_filename)16进制两两一组倒转:
import re
def reverse_hex_pairs(input_file, output_file):
"""将输入文件中的16进制字符串两两分组后组内倒转"""try:
# 读取原始16进制数据
with open(input_file, 'r') as f:
hex_data = f.read().strip()
# 清洗非法字符(仅保留十六进制有效字符)
clean_hex = re.sub(r'[^a-fA-F0-9]', '', hex_data)
# 补零处理奇数长度
if len(clean_hex) % 2 != 0:
clean_hex += '0'
# 分组并倒转组内字符
pairs = [clean_hex[i:i + 2][::-1] for i in range(0, len(clean_hex), 2)] # 关键修改
# 合并结果并写入文件
with open(output_file, 'w') as f:
f.write(''.join(pairs))
print(f"处理完成!输出文件:{output_file}")
return True
except FileNotFoundError:
print(f"错误:输入文件 {input_file} 未找到")
return False
except Exception as e:
print(f"处理失败:{str(e)}")
return False
if __name__ == "__main__":
# ========== 文件路径定义区 ==========
input_filename = r"output1.txt" # 输入文件路径
output_filename = 'output2.txt' # 输出文件路径
# 执行转换操作
reverse_hex_pairs(input_filename, output_filename)
man!!!